Capítulo 20 Importando banco de dados e exportando resultados
A importação de banco de dados nem sempre é uma tarefa fácil, principalmente se há negligência na estrutura do arquivo no qual se deseja importar. Logo, é importante primeiro conhecer o arquivo, saber de que forma os dados estão arzenados dentro do arquivo. Isto provavelmente irá lhe poupar horas de trabalho.
Não será abordado neste material todas as formas possíveis de importação de banco de dados mas apenas os mais utilizados. Caso não encontre neste material como importar o arquivo desejado, acesse a página oficial do CRAN no link https://cran.r-project.org/doc/manuals/r-release/R-data.html para maiores detalhes.
Serão abordados a importação de dados no seguinte formato:
- Cliboard (janela de transferência)
- TXT
- CSV
- XLSX
Quando um conjunto de dados está bem arranjado/estruturado então podemos nos deparar com dois tipos basicamente:
- Dado não-estruturado.
- Normalmente são provenientes de pesquisas do tipo observacional/levantamento.
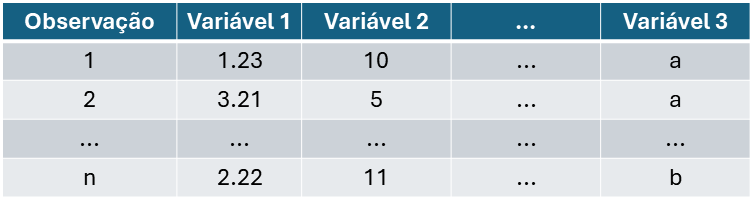
Figure 20.1: Layout de um dado não-estruturado
- Dado estruturado
- Normalmente proveniente de pesquisas do tipo experimental.
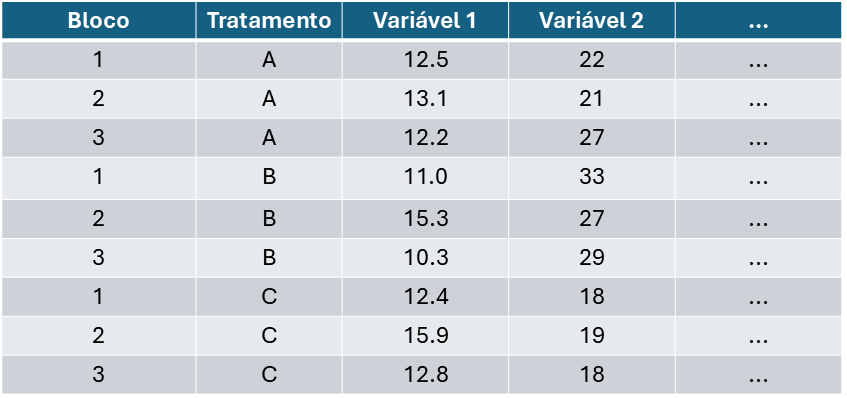
Figure 20.2: Layout de um dado estruturado
Se o conjunto de dados tem cabeçalho, evite palavras compostas e caracteres como acentos. Por exemplo, ao invés de utilizar Conversão Alimentar use conversao_alimentar.
Evite utilizar nomes longos do arquivo que será importado. Ao invés de utilizar dados do experimento da maria joaquina.xlsx utilize dadosJoaquina.xlsx ou dados_joaquina.xlsx.
Caso o arquivo a ser importado seja proveniente de uma planilha eletrônica (Excel por exemplo) e tiver outras análises e “penduricalhos”, faça uma cópia do arquivo e deixe nesta cópia apenas os dados que serão importados.
Lembre-se que os dados que serão importados não é para estar bonito e seguir as premissas da gramática. É para ser prático, limpo e funcional. Deixe as formatações para o relatório.
É possível ler dados caso eles não estejam nos formatos mencionados anteriormente. Entretanto, irá requerer um conhecimento de programação mais avançado e, mesmo assim, irá levar tempo para que os dados estejam no “formato” ideal para análise.
20.1 Método Clipboard
Chamamos de método e não formato porque justamente clipboard não é uma forma específica de arquivo mas, uma maneira de importar dados para dentro do R.
É útil quando queremos fazer uma análise rápida de um certo conjunto de dados. Entretanto, se pretendes fazer uma análise duradoura certamente este método não será útil e muito menos produtivo.
Neste caso os dados serão “copiados” de um arquivo (PDF, TXT, planilha eletrônica) e colocados na “área de transferência”. Uma vez realizado este procedimento podemos executar o código abaixo:
dad1 = read.table(file = 'clipboard',
sep = '\t',
header = TRUE)Obviamente que os dados precisam estar configura conforme as figuras 20.1 e 20.2.
20.2 Formatos TXT e CSV
As funções utilizadas para ler estes tipos de arquivos é nativa do R, ou seja, são as funções read.table e read.csv.
A função read.csv é um wrapper (invólucro) da função read.table. Portanto, basta sabermos utilizar apenas a função read.table.
Os principais argumentos da função read.table são:
file- É do tipo
string. Você deverá fornecer o nome completo do arquivo que deseja importar. Exemplo: “dados_soja.txt” ou “dados_soja.csv”.
- É do tipo
header- É do tipo
boolean. Por padrão éFALSE, ou seja, a função por padrão entende que não há cabeçalho no seu conjunto de dados. Caso haja cabeçalho, caso mais comum, então devemos informar no argumentoTRUE. sep- É do tipo
string. Você deverá informar qual é o caractere delimitador de colunas. Geralmente é um “espaço em branco”. Neste caso, não precisa informar nada. Em arquivos do tipo “CSV” é mais comum os delimitadores serem “,” ou “;”. Neste caso você deve fornecer tal informação no argumento.
- É do tipo
dec- É do tipo
string. Por padrão é “.”. Caso tenha colunas com decimais e cujo o separador de casas decimais seja “,”, então você deve informar tal separador para que a leitura dos números seja feita corretamente.
- É do tipo
stringAsFactors- É do tipo
boolean. Por padrão éFALSE. Se no seu banco de dados há uma coluna que não seja uma variável aleatória mas, um fator de estudo (tratamento), então é conveniente que informeTRUEneste argumento.
- É do tipo
- É do tipo
Para mais detalhes consulte help(read.table).
20.2.1 Exemplo 1: Baixe o conjunto de dados disponível no link https://lec.pro.br/download/R/dados/AndersonPg.txt. Certifique-se de que o diretório apontado pelo R é o mesmo do arquivo baixado. Segue o comando para checar o diretório atual do R
getwd()## [1] "C:/Users/ivana/OneDrive/IntroR/rmarkdown"Caso não seja o mesmo diretório, então é necessário sincronizar os diretórios. Caso esteja usando o editor Tinn-R veja a figura abaixo para escolher o diretório do arquivo do banco de dados.
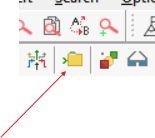
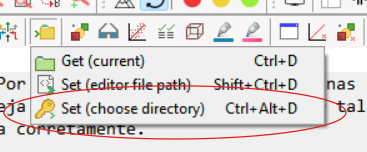
Figure 20.3: Interface do Tinn-R para mudança de diretório
Se não estiver usando o Tinn-R segue o comando genérico para mudar o diretório.
setwd('C:/Users/iballaman/OneDrive/Documentos/UESC/cursos_extensao/R/2024_2/basico/')Esteja atento de que a barra seja “/” e não “". Em seguida, sincronize os diretórios para importar o arquivo .TXT. Em seguida use:
dados = read.table("./dados/AndersonPg.txt")
dados## V1 V2
## 1 aeroporto volume
## 2 mem 9.1
## 3 mem 15.1
...Propositalmente perceba que o cabeçalho não foi interpretado adequadamente sendo considerado como um observação.
Neste caso é preciso especificar na função read.table o argumento head=TRUE para corrigir tal equívoco.
dados = read.table("./dados/AndersonPg.txt", head = TRUE)
dados## aeroporto volume
## 1 mem 9.1
## 2 mem 15.1
## 3 mem 8.8
...20.2.2 Exemplo 2: Considere o arquivo no formato .CSV disponível no link https://lec.pro.br/download/R/dados/milsa.csv.
O primeiro passo para ler um arquivo do tipo .CSV é descobrir qual é o caractere que está separando as colunas. Isto pode ser feito facilmente utilizando o Tinn-R ou qualquer editor de texto como o “bloco de notas” do Windows. Veja na imagem a seguir que o caractere “ponto e vírgula (;)” está delimitando as colunas.
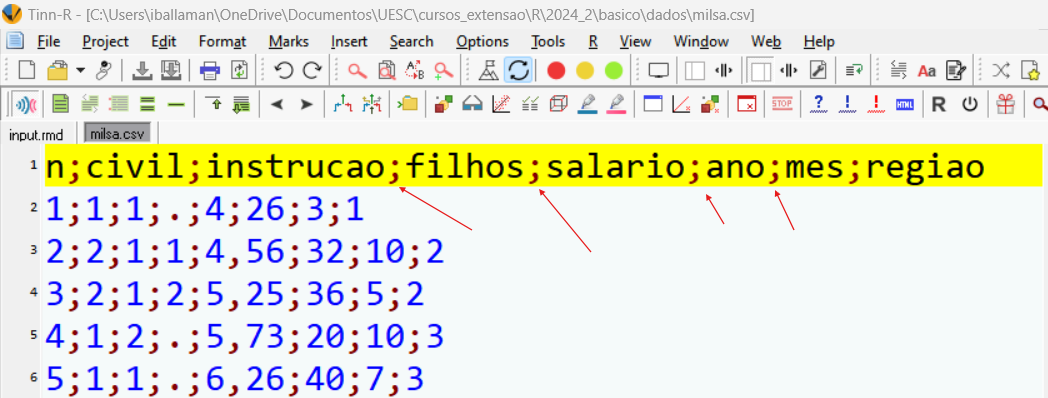
Figure 20.4: Interface do Tinn-R enfatizando o separador de colunas vírgula nos dados
Perceba que há neste arquivo pontos (“.”) no lugar de dados e que o separador de casas decimais é “,”. Logo, no momento em que fizermos a importação dos dados precisaremos informar a função read.table todas essas características.
dados = read.table("./dados/milsa.csv", head = TRUE, sep = ";", dec = ",", na.strings = ".")
dados## n civil instrucao filhos salario ano mes regiao
## 1 1 1 1 NA 4.00 26 3 1
## 2 2 2 1 1 4.56 32 10 2
## 3 3 2 1 2 5.25 36 5 2
...Ao chamar a função summary percebemos que todos os dados foram interpretados adequadamente.
summary(dados)## n civil instrucao filhos salario
## Min. : 1.00 Min. :1.000 Min. :1.000 Min. :0.00 Min. : 4.000
## 1st Qu.: 9.75 1st Qu.:1.000 1st Qu.:1.000 1st Qu.:1.00 1st Qu.: 7.553
## Median :18.50 Median :2.000 Median :2.000 Median :2.00 Median :10.165
## Mean :18.50 Mean :1.556 Mean :1.833 Mean :1.65 Mean :11.122
## 3rd Qu.:27.25 3rd Qu.:2.000 3rd Qu.:2.000 3rd Qu.:2.00 3rd Qu.:14.060
## Max. :36.00 Max. :2.000 Max. :3.000 Max. :5.00 Max. :23.300
## NA's :16
## ano mes regiao
## Min. :20.00 Min. : 0.000 Min. :1.000
## 1st Qu.:30.00 1st Qu.: 3.750 1st Qu.:1.000
## Median :34.50 Median : 6.000 Median :2.000
## Mean :34.58 Mean : 5.611 Mean :2.028
## 3rd Qu.:40.00 3rd Qu.: 8.000 3rd Qu.:3.000
## Max. :48.00 Max. :11.000 Max. :3.000
## 20.3 Formato “XLSX”
É o formato da planilha eletrônica do pacote Office da empresa Microsoft, mais especificamente do Excel.
Existem alguns pacotes que permitem importar arquivos no formato “.XLSX” como: readxl, openxlsx,openxlsx2, xlsx e writexl.
Iremos utilizar neste curso o pacote openxlsx devido os autores do curso estarem mais familizarizados. Os usuários podem consultar a documentação de ajuda dos demais pacotes citados caso tenham interesse.
Partindo do princípio que as premissas estejam de acordo, a leitura do formato “.XLSX” é direta e simples. Seguem os principais argumentos da função read.xlsx.
sheet- É do tipo
numeric. Indica qual aba da planilha você deseja importar. Por padrão é a aba 1.
- É do tipo
detectDates- É do tipo
boolean. Por padrão éFALSE. Se existem datas formatadas na sua planilha, então deve modificar este argumento paraTRUE, caso contrário as datas não serão reconhecidas.
- É do tipo
Para maiores detalhes consulte a documentação do pacote.
20.3.1 Exemplo 3: Considere o arquivo no formato .CSV disponível no link https://lec.pro.br/download/R/dados/cursor2021.xlsx.
library(openxlsx)
dados_geral = read.xlsx("./dados/cursor2021.xlsx")
dados_geral## Idade Sexo Ocupação
## 1 30 Feminino Aluno de graduação da UESC
## 2 20 Masculino Aluno de graduação da UESC
## 3 25 Masculino Aluno de pós-graduação da UESC
...Muito simples ler dados do Excel desde que, no seu arquivo Excel não haja nenhum “resíduo” de outras análises, ou seja, só há os dados que deseja importar.
Percebam que há dados em uma outra aba. Vamos utilizar o argumento sheet para indicar que queremos ler os dados de tal aba.
library(openxlsx)
dados_grad = read.xlsx("./dados/cursor2021.xlsx", sheet=2)
dados_grad## Idade Sexo Ocupação
## 1 30 Feminino Aluno de graduação da UESC
## 2 20 Masculino Aluno de graduação da UESC
## 3 24 Masculino Aluno de graduação da UESC
...20.3.2 Exercícios
- Baixe e carregue o seguinte conjunto de dados: https://lec.pro.br/download/R/dados/AndersonPg1.txt. Após a importação estime por tipo de filial: média, variância, desvio padrão, mínimo, máximo, coeficiente de variação. Faça um histograma e um boxplot para cada tipo de filial. Como você expressaria a estimativa da média em um artigo científico?
20.4 Exportando resultados
A melhor forma de exportar resultados certamente é aquela que combina o texto que você deseja escrever juntamente com o resultado que desejas expor. Para isso, é necessário que tenhas conhecimento básico de LaTeX ou Markdown para elaborar relatórios belíssimos em conjunto com a linguagem R. Se pretendes alcançar este nível visite o site https://rmarkdown.rstudio.com/ para ver exemplos e se encantar com a vasta possibilidades de gerar documentos das mais variadas formas utilizando R e Markdown. Como a linguagem Markdown é simples, provavelmente conseguirá gerar seus primeiros relatórios. Mas aconselho também que estude a linguagem LaTeX para ampliar seu arsenal de escrita de relatórios automáticos.
Os comandos que iremos mostrar a seguir irá lhe poupar tempo do comando “CTRL + C” + “CTRL + V”.
Quando se tem um script longo e que provavelmente irá utilizá-lo mais de uma vez, é conveniente que carregue os resultados no ponto em que parou ao invés de executá-lo novamente.
Primeiro, salve todos os objetos e resultados da seguinte forma:
save.image('CursoR.RData')Quando for utilizar o script novamente carregue o arquivo .RData que foi salvo.
load('CursoR.RData') # Para carregar o que foi feito e executado.A técnica exposta anteriormente não é um “método de exportar resultados”. Entretanto, pode ser útil nas situações no qual ainda não exportou os resultados e, queira carregar as análises rapidamente para tal finalidade.
Para exportar resultados de uma maneira simples pode ser utilizado a função sink. Com esta função é possível salvar os output e message.
Os formatos no qual se é possivel salvar são: “.doc” e “.txt”. Caso tente salvar no formato “.docx” o arquivo não irá abrir. Não sei o motivo!
O arquivo será salvo no diretório atual de execução do R. Sempre que há dúvida qual é o diretório atual em execução, use o comando getwd().
Segue um exemplo:
# -----------------------------------------------------------------------------
# Salvando os resultados
# -----------------------------------------------------------------------------
sink('analysis.doc',
type = 'output')
summary(iris)
media = mean(iris$Sepal.Length)
media
sink()Caso queira salvar tabelas nos mais variados formatos como matrix, data.frame, tables os exemplos a seguir serão úteis.
# -----------------------------------------------------------------------------
# Salvando matrizes e data.frames em excel
# -----------------------------------------------------------------------------
tabsimp = rep(c('Mulheres',
'Homens'),
c(20, 12))
tabsimp1 = table(tabsimp)
write.table(tabsimp1, # O objeto a ser salvo
'tabsimp.xlsx', # O nome do arquivo
row.names = FALSE, # Com nome das linhas???
quote = FALSE) # Com aspas??
write.table(modmean,
'modmean.xls',
row.names = FALSE,
quote = FALSE,
sep = '\t') # Separar as colunas
write.table(iris,
'iris.xlsx',
row.names=FALSE,
quote=FALSE)