
![]()
![]()
![]()
Descrição
O Algoritimo de Agrupamento de ScottKnott (The ScottKnott Clustering Algorithm - ScottKnott) é um pacote para o R.
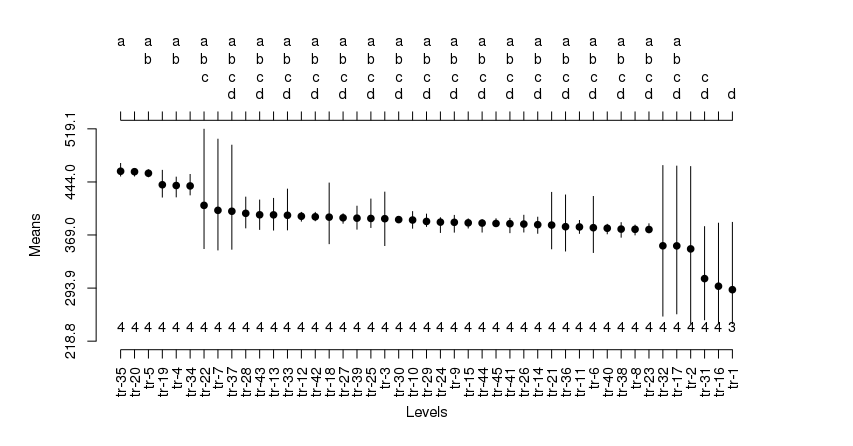
Possui muitos recursos que possibilitam e facilitam o uso do algoritmo de Scott, A.J. e Knott, M. para descriminar os fatores qualitativos que provocam variação na variável de resposta subsequente a uma análise de variância (ANOVA) no R. Possibilita e facilita a análise numérica detalhada e a contrução um gráfico elegante e informativo.
É um projeto registrado sob a Licença Pública Geral GPL, sendo portanto software livre.
Objetivo
O objetivo do desenvolvimento do pacote ScottKnott foi aumentar o suporte do ambiente R aos tipos de análise às quais ele se aplica: dados estruturados (ou provenientes de delineamentos e esquemas experimentais) quando o fator que provoca variação na variável de resposta analisada via ANOVA possui níveis categóricos e se pretende discriminá-los. Esse tipo de análise é uma das principais (e tradicionais) técnicas da estatística univariada de dados estruturados.
O início de seu desenvolvimento data dos primeiros contatos do primeiro autor com o R (2007/2008). O R não oferecia recursos (em linguagem de alto nível: simples e flexível) para essas análises. Esse fato tornava essas análises trabalhosas para serem feitas rotineiramente. A demanda inicial foi apresentada pelo prof. Sérgio J. R. de Oliveira, pois esse "teste" era muito usado na Universidade de Lavras (onde ele havia feito uma especialização) e ainda não estava disponível no ambiente R - para o qual a maioria dos professores da Área de Estatística do DCET/UESC estavam migrando. Esse foi o início do atual pacote. Dai por diante, progressivamente, foi ganhando novos recursos (alguns por solicitação, outros por contribuições voluntárias dos usuários) até chegar ao estágio de desenvolvimento atual.
Particularidades
O algoritimo de agrupamento de ScottKnott apresenta uma característica que o distingue dos demais testes de comparação de médias múltiplas: não ocorre sobreposição dos tratamentos. Ou seja, um mesmo tratamento não pode ser classificado em mais de um grupo. Em outras palavras, os grupos são auto-excludentes.
Embora exista divergência se ele pode/deve ou não ser classificado como um teste inferencial clássico (como o teste de Tukey) é muito usado por melhoristas, principalmente nas situações onde o grande número de tratamentos dificulta sua discriminação nos testes clássicos. Entretanto, vários estudos desenvolvidos no Brasil confirmam suas boas características. Estudos demonstram que ele apresenta uma convergência muito boa com o teste de Tukey no tocante a discriminação e p-valores.
Em decorrência dessa divergência de opiniões, optou-se por não o chamar nessa página de Teste de ScottKnott, embora isso seja comum em artigos científicos e textos acadêmicos.
Principais características
- Possibilita e facilita a aplicação do algoritimo de agrupamento de Scott, A.J. e Knott, M. nos principais delineamentos (Delineamento Inteiramente ao Acaso - DIC, Delineamento em Blocos Casualizados - DBC, Delineamento em Quadrado Latino - DQL) e esquemas experimentais (Experimentos Fatorias - EF, Parcelas Sub-Divididas - PS, Parcelas Sub-Sub-Divididas - PSS)
- Apresenta os resultados em agrupamentos seguidos de letras em sua forma convencional
- Facilita o desdobramento das possíveis interações entre os fatores nos seguintes esquemas experimentais: EF, PS, PSS
- Possibilita e facilita a contrução de um gráfico que discrimina os tratamentos apresentando: as estimativas das médias, opções de medidas de dispersão, os grupos de classificação além do número de repetições a partir das quais as médias foram estimadas
- Aceita como input objetos das classes:
- Vetores
- Data.frame(s)
- Matrize(s)
- aov
Autores
- Enio Galinkin Jelihovschi - Brasil/UESC/DCET (Principal autor)
- José Cláudio Faria - Brasil/UESC/DCET (Co-autor)
- Ivan Bezerra Allaman - Brasil/UESC/DCET (Co-autor e mantenedor)
Download